编译原理笔记2024-9-24
24/9/2024
Tiger Language
八皇后问题

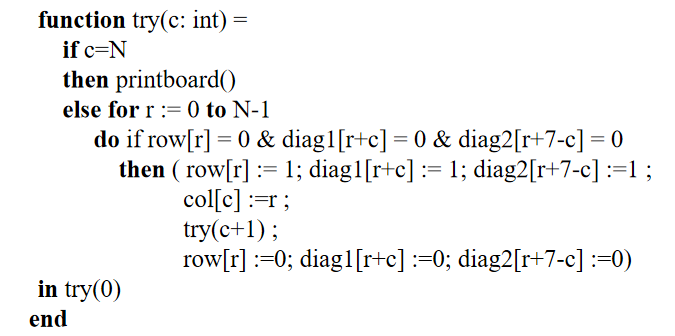
Tiger 语言主要是表达式,类似于一种函数。前面会有定义,定义完之后再调用执行try。前面是定义:有变量定义var, 有类型定义 type,有函数定义function 。后面的函数中有控制语句,循环语句,:= 赋值,=判等。**注意: **Tiger 语言为了保持简单性 building type 只有int 和string,没有浮点数及其计算。 这个例子是用tiger语言模拟八皇后问题。(书上366页
Merge sort



函数:返回值写在函数名字后面:int,函数可以嵌套。在ICS中,i要么应该是栈上的局部变量,i要么是全局变量。这里i也应该在栈上的,理论上另一个函数应该是没有办法访问到的。在C中是没有碰到过的,而在tiger中会作为一个问题。
结构:List是一个record结构类型,l是list类型变量,nil是一个空指针。在tiger中没有显式的pointer变量声明,而在此array变量和record都是指针。我们在C中如果说一个变量是一个structrue,array代表了这个首地址,而structure代表了内存中的一块东西。这里就是判定一个array或者一个record有没有初始化。

递归的两个函数或者是结构必须定义得是挨着的。上面的tree和treelist互相调用递归;下面是函数递归;

上节课我们讲过,给一个source program,出来一个汇编。前端:把source变成计算机更加容易处理的数据结构。比如lab1中变成了一个tree和一个table,这就在计算机上非常容易做了。我们从第二章~第五章,我们要做的事情就是把程序变成树和表,让程序自动来做。就是把用source language表示的程序翻译成用token(变量,函数…)构成的段落文章,当然这里包含两步,一步是翻译成词(词法分析),一步是构成文章(语法分析)。
词法分析(Lexical Analysis)

词法分析要把字符串序列变成token序列,其实就是下面两件事:
- 划分:tab是没用的,if是一个对象,==又是一个pattern,我们把这样的序列做一个切分,然后做一个分类。
- 分类:比如tab、空格、回车都是没用的东西,i、j、z都属于变量,if、else都属于关键字。
词法分析后就变成了一个token串。token其实可以看作是一种类型。
- 在自然语言中有名词,动词,然后有主谓宾之类的。
- 在程序设计语言中,比如有identifier,keyword,integer,relation(==), whitespace(tab, space, enter)。
我们把字符串变成token串以后,对于我们的语法分析就很重要。我们的语法分析是基于这个token串来做的。
Token定义

- token就是一个集合(变量[一定是字母开头]集合 / 关键词……)
- Lexeme是集合当中的一个元素(Lexeme构成了token)(比如i,j,==都是集合中的元素就是lexeme)
- Non-token就是我们的注解的一些宏定义,就需要用预处理去处理掉。在tiger中,comments是可以嵌套的,允许/* /* */ */的嵌套匹配。
如何实现这种解析

就是划分出子字符串,以及lexeme属于的类;然后返回给parser。下面以刚刚的字符串为例:

把一串字符串序列,挨个解析,转化成一个token-lexeme串生成出来。
通常会把认出的无意义的东西直接扔掉,不会留给parser
问:是否可以预处理 比如先把comments和whitespace先处理掉呢?有些程序是可以的,有些程序是不行的。比如:

如果这里的空格如果被处理掉了,本来应该出错的地方就编译通过了。Fortran里头是,有没有这个空格没事,一概会被处理掉。
Ps: 这里有两个重要的点:
- lexer的目标是对字符串进行分区:是从左往右的逐个token的识别
- 提前看:去决定token的上一个结束和下一个起始位置(特别是fortran中)
举个例子: 在这个语言中DO相当于是for,这个句子DO 5 I =1,25意思是,I从1到25枚举,结束之后跳到第5行(label)执行;解析这个语句时:在我看到逗号之前不知道这是什么东西,所以要提前看。因为空格会自动去除,如果把逗号写成了句号,就会把循环写成一个DO5I的变量赋值。
在这个语言中DO相当于是for,这个句子DO 5 I =1,25意思是,I从1到25枚举,结束之后跳到第5行(label)执行;解析这个语句时:在我看到逗号之前不知道这是什么东西,所以要提前看。因为空格会自动去除,如果把逗号写成了句号,就会把循环写成一个DO5I的变量赋值。
下面我们要介绍怎么划分字符串,然后分类成token;刚刚说过了,token是一类字符串的集合。那字符串到底分几类呢?用自然语言来讲:要么是一个有限的集合,要么是字母开始的变量,要么数字开头的非空数字串。用形式化语言来描述:正则语言+上下文无关文法。
正则语言(Regular Language)
我们先用regular language来描述token。这种语言简单实用,通俗易懂。

这个定义说白了就是定义了一个字母表,Tiger语言中的字母都来自这个字母表。就像在英文字典里单词是合法的,但是不在字典中的就不是。这里也一样不是所有的ASCII组成的字符串都是合法的。
对于合法的字符串,也会判断它的类型,这就需要 regular expression 来描述。正则表达式是正则语言的一个notation,A是一个表达式,它所描述出来的那些字符串,就是一个语言L(A)。正则表达式有三类:
- single character:

- Concatenation:

- Union:

刚刚是有限的,下面是无限的:
token 的分类:
Keyword

就是C语言中常见的关键词
Integer

一串数字组成整数
Identifier

变量名一定以字母开头的,后面可以跟任意多的字母和数字
Whitespace

Whitespace包含空格、tab和回车
有了这些,下面可以详细说一下如何实现词法解析:
先要确定好 number、keyword、identifier,也就是 Tiger 语言中的词法成分
用regular expression定义token(刚刚确定好的那几个)
一定要规定好符合上述条件的各自的字符串,然后如果s符合条件,一定知道属于哪一类

找到输入的字符串的子字符串符合条件—->属于哪一类,然后remove已经解析完的继续解析
最大吞噬原则(Maximal Munch)

我们碰到F一定是和identifier match的,一个个匹配完remove掉。这里显得很简单,换一个
这里有三个漏洞,分别举三个例子:

如果f匹配了直接remove,就会出问题,我们发现到了foo还是,还是foo+不是了。我们还要尽量往后看,这就不是正则语言能干的事情了。需要:Maximal munch规则:如果都属于L(R)的话,我们要选择更长的。

我们要把这个语言改一改,加了一个keyword叫做new,new既满足keyword还满足identifier。当同时满足的时候,我们选择前边的这个,也就是优先级规则,需要在规则中制定好优先级。

出错机制:出错的字符串要有归属,所有以规则里要加上。
至于怎么判断一个字符串是否符合某个token的定义,需要有限自动机,下节课讲。
总结一下今天主要讲的就是如何进行词法分析:把字符串转变为token串,这就要利用正则表达式进行解析,其中遵循两个原则:最大吞噬原则和优先级原则。




